Powering Standards with Code: The Role of Open Source in CDISC 360i
- Presentation given at the PHUSE SDE 2025 in West Windsor (NJ) on July 23rd, 2025 by Sam Hume
- Opinions are my own
Speaker Notes
I’m going to talk about the CDISC 360i program and how we’re using code and open-source software to power standards. This covers both standards implementations and standards development.
360i: Powering Standards with Code
Turning data standards from static specs into dynamic, executable solutions
- Standards implementation focus
- Solutions over specifications
- Code as part of standards development
- Consider the HL7 FHIR example
Speaker Notes
Standards specifications play a necessary, but not sufficient role in automating our research data pipelines. Standards implementers want solutions. To have solutions that implement our specifications we need code. We want code that can automate our research data pipelines. We want code to demonstrate and test the standards. Code, as a reference implementation, communicates how to apply the standards and process data. Code can provide documentation and serve as a training tool.
HL7 FHIR provides a useful example of a standard that has a technology focus. It’s really easy to get started with FHIR because they have a wide range of open-source tools, test servers, test data, and open standards specifications. You can start building stuff right away. FHIR does many things right, but to me, the way they’ve integrated OSS tooling into their DNA is where the magic happens.
360i Deliverables
Publish executable study packages that include open-source tools
- Executable study package
- Standards Packages
- Implementation Cookbooks
- Example Implementations
Speaker Notes
360i focuses on standards implementations, on building out an automated, standards-driven research data pipeline. A definition of done is when we have the standards metadata for a study that we combine with test data and open-source tooling to publish an executable study package. You will be able to download and run this package. Open-source tooling represents an essential component of this package - you can’t run the study package without it.
We also plan to publish a cookbook that will contain recipies for common, tested ways of processing the standards metadata to drive the automated research data pipeline. These recipes will make it easier for others to generate software tools, OSS and commercial.
CI/CD for CDISC
Treating standards as code: version-controlled, testable, and automatable
- Test standards in an automated pipeline context during development
- Test data is part of standards development
- Ensure tooling is available when new standards are released
- GitHub as a standards development platform
Speaker Notes
Consider taking this further, and implementing CI/CD as part of standards development. That represents a pretty big shift in how we develop and maintain standards. Standards are tested as they’re developed. Not only is the standard under development tested, but it can be tested in the context of the end-to-end study data pipeline. In this way, we’re treating standards like code. Or, standards are being developed and managed using many of the same techniques and methods we use for developing code.
In future Public Reviews, it would be great to publish a standards package that includes metadata that you can run and test and provide feedback on what breaks.
360i Automated Pipeline
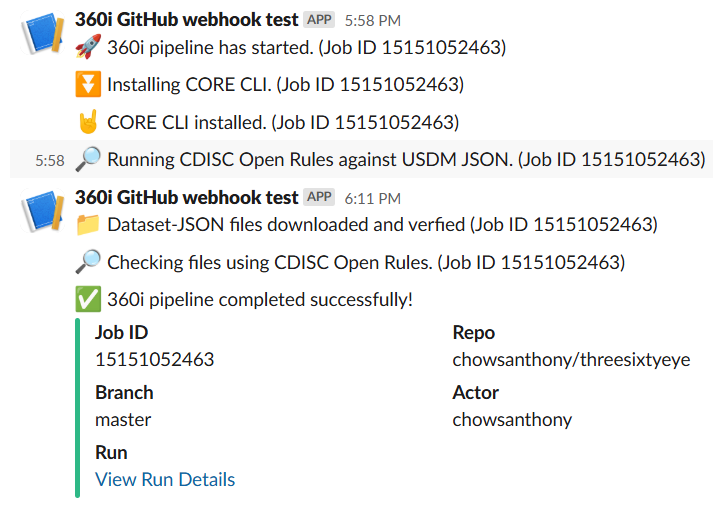
Speaker Notes
Here you can see we’ve already started to build an automated pipeline where we can automatically build and run the study package using GitHub. This is the beginning of an automated pipeline. This same approach should be used for standards development, such that when you check in a change with some test data, it triggers a set of tests using OSS tools.
Why Open-Source Software for 360i?
Code is becoming a critical part of data standards
- 360i seeks to promote a common set of tools for standards-driven automation
- Promotes consistency and interoperability while lowering barriers to adoption
- New sophisticated standards models, like USDM, require tooling to use
- Pharmaverse / PHUSE collaboration
Speaker Notes
There are all kinds of reasons CDISC should be engaged in open-source for 360i, I’ll touch on a couple. Common tooling can help deliver common work flows and data flows. By common tooling, I mean you should be able to download open-source tools with a reasonable expectation that it will run in your environment with your standards; the OSS equivalent of COTS. That’s not something we’ve had in the past. Common tooling reduces standards variability by processing standards and data using common methods and dataflows. It lowers barriers to adoption by making it easier and less expensive to adopt the standards, but also by ensuring that free tools are available.
As a practical operational matter, CDISC needs tools that anyone can use without licensing getting in the way since our volunteers come from all over.
Providing the means to develop and test standards and tools together will improve the standards, make them easier to implement, and make it possible to extract much more value from your investment in standards.
Open source provides a shared foundation for innovation and collaboration. Characteristics like honesty, transparency, and reproducibility are enhanced through the use of open-source tools. In our industry we value standards, reusable components, and collaborative problem-solving.
The hackathons have been very productive. Our Dataset-JSON Viewer hackathon produced some great tools and addressed a named MUST HAVE requirement for Dataset-JSON adoption. It’s a great way to address the need for new tools and new features for existing applications.
Important to note: (1) OSS is not part of the standards, they’re part of the standards development process, (2) OSS will be predominantly developed by the community, not by CDISC, and (3) CDISC does not plan to endorse a specific package and will work with multiple OSS tools where possible.
360i Phase 1 Roadmap
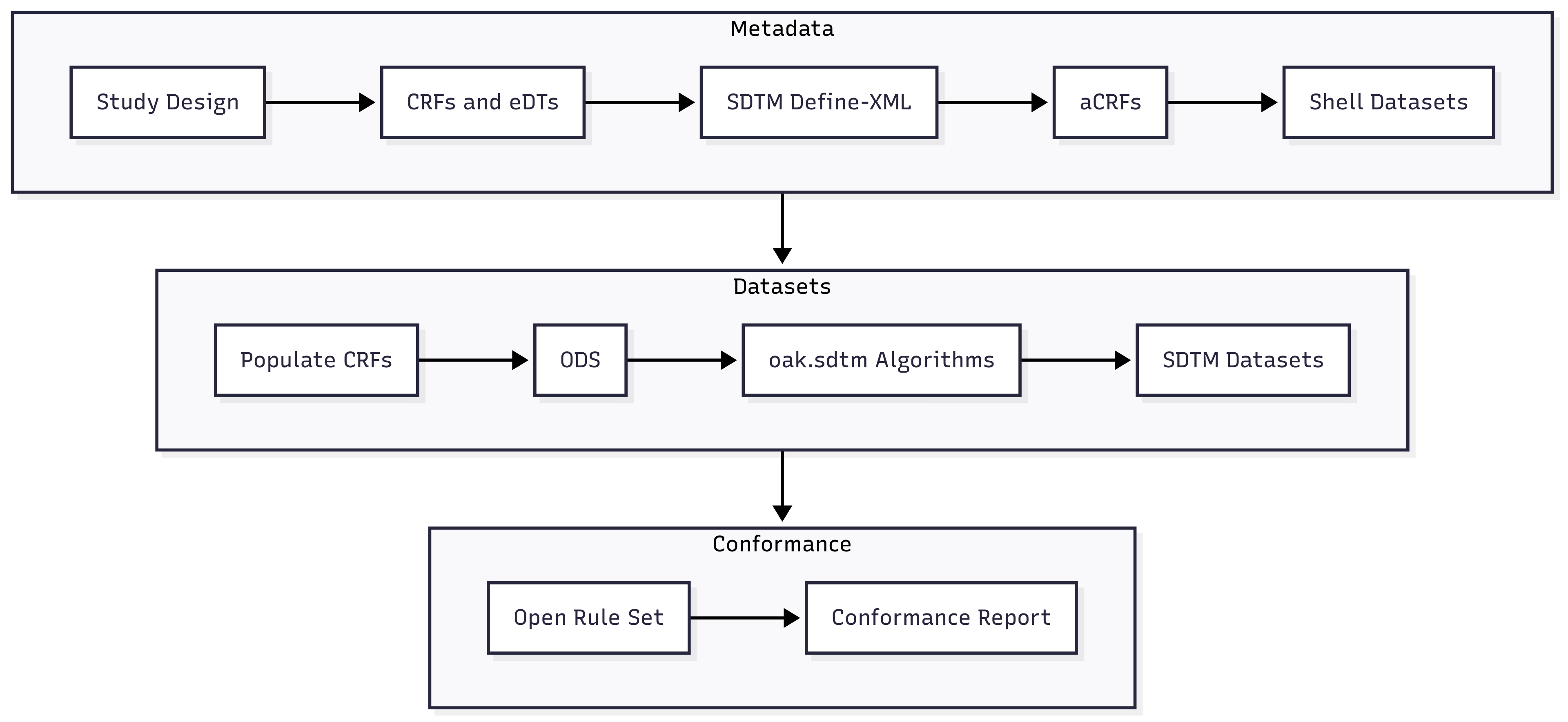
Speaker Notes
Now I’ll get into more specifics about the 360i program. Here’s our 360i Phase 1 roadmap. Given that our goal is an automated end-to-end pipeline, I think you’ll find pretty much what you’d expect on this roadmap. We’re generating lots of the metadata artifacts, like CRFs and Define-XML. We’re also including test data to generate the SDTM datasets. And then using the CDISC Open Rules and CORE to test for conformance.
Phase 1: Study Design through SDTM Generation
New approaches to old problems
- Using USDM + BCs + DSS to drive automated SDTM generation pipeline
- Identifying and filling gaps in the process
- Creating recipes that will allow the development of common tools
- Uses Open Study Builder, sdtm.oak, odmlib, Dataset-JSON tools, etc.
Speaker Notes
So, while the roadmap I just shared should be very familiar in the sense that you’re already producing these artifacts, in 360i we’re doing some innovative things that you are not yet doing. We’re using the USDM model + BCs + DSSs to increase the levels of automation and consistency in these processes. We are, necessarily, filling gaps in the standards and asking questions about how metadata should be sourced. We will be creating recipes for our cookbook that spell out the steps for implementing the standards metadata, in this case using USDM, BCs, and DSSs. And, we’ll be using quite a few existing open-source tools that you will find on COSA, including OSB + sdtm.oak, Dataset-JSON conversion tools and viewers.
Phase 2: ADaM through TLF Generation
Phase 2 is where we focus on clinical reporting
- Defining Analysis Concepts
- Makes use of the ARS standard
- Uses the Phase 1 SDTM datasets as input
- Will use siera, Admiral, and other Pharmaverse packages
Speaker Notes
Phase 2 may be what many of you find most interesting as it includes the clinical reporting part of the process. It takes the SDTM datasets and artifacts generated in Phase 1 and then generates ADaM, analysis datasets, and TLFs. Currently, Phase 2 is working on defining analysis concepts, and these will play an import role in automating the reporting process. Phase 2 will make use of ARS. It will use existing open-source to include quite a few Pharmaverse packages. If you want to influence what gets produced here, I’ll touch on how to get contribute at the end of the presentation.
Example: Automated SDTM Define-XML Generation
Replace manual metadata sourcing with reusable recipes and code
- What’s different about 360i: use USDM + BCs + DSSs
- USDM + BCs + DSSs are not sufficient
- Plan to generate metadata templates from a variety of sources
- Sustaining vs. disruptive innovation
Speaker Notes
I thought I’d share one example of a 360i subteam to make this concrete. I’m part of a small subteam working on automating the SDTM Define-XML generation. Again, we’re driving this from the study design SOA in USDM to include BCs and DSSs. Once we’ve sorted out the best way to source the metadata needed to drive automated Define-XML generation we’ll create a recipe to describe that process. A goal will be to enable the development of common tools that we can use that eliminate much of the manual sourcing of metadata, which has always been the hard part of generating a Define-XML.
Although, arguably, USDM is a disruptive innovation, much of the pipeline reflects existing data flows or methods. So, yes what we’re doing here is very innovative. But, we also recognize that as CDISC celebrates 25 years as an SDO, that there’s an opportunity to do something very disruptive and change how we apply these standards that’s very different from today. I don’t have the time to cover that today, but suffice it to say, we’re working on that as well. That’s a longer term vision.
Lucy, you’ve got a lot of explaining to do
360i open-source gives us the bazaar; a messy, fast-moving place where innovation happens
- The cathedral and the bazaar – Eric Raymond
- Coding, as with painting, starts with sketching – Paul Graham
- Plan to throw one away; you will, anyhow – Fred Brooks
- Open-Source as experimentation and communication: Sandboxes
Speaker Notes
At this early stage in 360i, we’re experimenting to learn how to best apply the USDM + BCs + DSS as well as determining standard ways of sourcing the other Define-XML metadata. The goal is to create a recipe and associated software to more completely automate Define-XML generation in a way that anyone could implement.
This effort is a lot more like a bazaar than a cathedral, referencing Eric Raymond’s book The Cathedral and the Bazaar. It’s not a traditional software project like you’d find at most vendors or in most organizations. It’s drawing lots of ideas and contributions from different folks that are working in different technologies and with slightly different requirements. To draw from another early open-source book, coding, as with painting, starts with sketching. That’s what we’re doing now. Code is how we sketch. Much of this code may be replaced or refactored as we proceed. The main point is learning and sharing code as open-source as a way of explaining what we’re working on. And, we’re planning to throw one away, as Fred Brooks famously stated in the Mythical Man Month.
This is one way of using code to power standards. As we run our experiments and find gaps in the standards, we will propose changes to the standards. The code helps test the standards and explain how we’re applying them towards our goal of an automated end-to-end process.
Dumbing it Down
Open-source is how we scale standards adoption
- Code libraries make it simpler to implement complex data standards
- Abstractions in code are essential to simplifying implementation
- Code helps reduce the variability in standards implementations
- See FHIR and OMOP as examples where tooling plays a major role
Speaker Notes
Reducing complexity and simplifying standards implementations is another key benefit of using code to power standards. We need code libraries and packages to make it easier to build tools. The abstractions and default settings are key to simplifying standards implementations. Abstractions hide some of the complexities in the CDISC standards. Open-source software tools help non-techies have an easier time implementing the standards.
Using these common libraries and tools will reduce the variability in standards implementations that will make it easier to understand the standards and aggregate datasets across studies. Using more default settings reduce standards variability.
We’re also lowering the barrier to standards adoption by making them simpler and less expensive to implement. At the same time, we’re making it easier to get the full value out of your investment in standards.
OSS and Risk Taking
Open-source enables innovation that commercial models often can’t
| Factor | Open-Source | Commercial | |———————–|————-|——————————-| | Speed of Innovation | Often faster | Slower but more polished | | Scope of Innovation | Broader and grassroots | Focused; customer-driven | | Community Involvement | High | Low to none | | Risk Taking | High | Lower (ROI focused) | | Resource Constraints | May limit scope | Can fund ambitious R&D | | UX and Enterprise Fit | Often weaker | Often stronger |
Speaker Notes
Risk-taking is another key benefit of open-source that makes it essential to the 360i program and CDISC in general. I think there’s plenty of evidence that open-source developers are willing to take risks that most commercial vendors will not. This is not a dig on vendors. They’re more focused on controlled development, addressing customer needs, and ROI. Open-source vendors do not have the same constraints and tend to be much more open to taking on projects that might one day have a big impact.
I believe open-source and commercial vendors both play an important role in our ecosystem. And, they’re not mutually exclusive. Lots of commercial vendors benefit from open-source libraries and tools, and sometimes open-source developers benefit from contributions from commercial vendors.
A great example of risk-taking can be found in the Dataset-JSON tooling. We actually ran the first Dataset-JSON Hackathon just before v1.0 was released. This was before there were any supporting public comments from the FDA. Folks jumped in there and created lots of tools, including the conversion tools. The conversion tools allowed us to start the PHUSE/CDISC/FDA submissions pilot. Without those tools, that pilot doesn’t happen. During the pilot some feedback included a critical need for Dataset-JSON Viewers. We recently completed that hackathon and a number of great tools were produced. This risk-taking is helping to drive change. This does not happen or happens at a much slower pace, without open-source and risk taking.
Call to Action
The future of standards depends on who shows up
- Participate in the 360i program: https://www.cdisc.org/cdisc-360i
- Submit solutions to COSA for listing: https://cosa.cdisc.org
- Participate in COSA-sponsored hackathons to accelerate 360i
- Contribute to standards content creation
Speaker Notes
The future of standards depends on who shows up and contributes. If we want this future where standards are powered by code, CDISC needs more people like those of you building tools to get involved. There are lots of opportunities to contribute to and influence 360i, and we haven’t really started the clinical reporting in phase 2 yet.
Another way to participate will be through hackathons. We’re planning to fill gaps in what software covers in part through hackathons, so keep an eye out for future hackathon announcements. If you have an open-source tool that you believe is a fit for 360i, and it’s not part of COSA, please consider applying.
If you’re not slinging code, there are also plenty of opportunities to work on standards content. Remember, 360i will also be about making the standards easier to automate in an end-to-end pipeline.
Questions?
If we want standards to be usable, they need to be executable, and that starts with us. I’d love to hear your thoughts.
Speaker Notes
Said differently, to maximize the benefits of standardization, the standards need to be executable. Open-source developers will play the lead role in making this a reality.
Reference: USDM + BC + DSS
| Standard / Program | Reference |
|---|---|
| USDM | https://www.cdisc.org/ddf |
| Biomedical Concepts | https://www.cdisc.org/cdisc-biomedical-concepts https://github.com/cdisc-org/COSMoS/tree/main/bc_starter_package |
| Dataset Specializations | https://github.com/cdisc-org/COSMoS/tree/main/bc_starter_package |
| CDISC 360i | https://www.cdisc.org/cdisc-360i |
Reference: CDISC 360i Phase 1 OSS
| Application | Repository |
|---|---|
| CDISC Library Client | https://github.com/cdisc-org/cdisc-library-client |
| CORE | https://github.com/cdisc-org/cdisc-rules-engine |
| CORE Rule Editor | https://github.com/cdisc-org/conformance-rules-editor |
| CDISC ODM-XML CRF SDTM Annotations | https://github.com/jmangori/CDISC-Define-XML-SAS-XMLMAP |
Reference: CDISC 360i Phase 1 OSS (continued)
| Application | Repository |
|---|---|
| Dataset-JSON Conversion (SAS) | https://github.com/lexjansen/dataset-json-sas |
| Dataset-JSON Conversion (R) | https://atorus-research.github.io/datasetjson/index.html |
| Dataset-JSON Viewer | https://github.com/defineEditor/vde-dataset-viewer |
| Define-XML Stylesheet | https://github.com/lexjansen/define-xml-2.1-stylesheets |
Reference: CDISC 360i Phase 1 OSS (continued)
| Application | Repository |
|---|---|
| odmlib | https://github.com/swhume/odmlib |
| Open Study Builder | https://github.com/NovoNordisk-OpenSource/openstudybuilder-solution |
| sdtm.oak | https://github.com/pharmaverse/sdtm.oak |
| Study Definitions Workbench | https://github.com/data4knowledge/study_definitions_workbench |